InternLM模型实战
在大模型实战营的学习中,我完成了一次完整的 LLM 开发实践。从搭建开发环境、配置 SSH 连接,到利用LLM运行第一个程序、完成 LeetCode 算法题,再到利用 Hugging Face 平台下载与上传模型,我一步步深入掌握了实际开发中的常用工具链。
随着学习的推进,我尝试了更复杂的任务:结合 LlamaIndex 构建 RAG 应用,使用 XTuner 对 InternLM 模型进行微调,并最终通过 OpenCompass 完成了模型评测。整个过程不仅让我对书生系列模型(InternLM2.5)的强大能力有了更直观的认识,也让我系统性地掌握了从模型调用到定制优化、再到效果评估的完整技术流程。
这是一次从理论到实践、从基础到进阶的完整学习旅程,希望这篇记录能为同样在 LLM 开发路上探索的朋友提供一些参考。
L0G1000
创建开发机并进行SSH连接
创建开发机
首先进入InternStudio官网,登录账号后找到创建开发机的位置
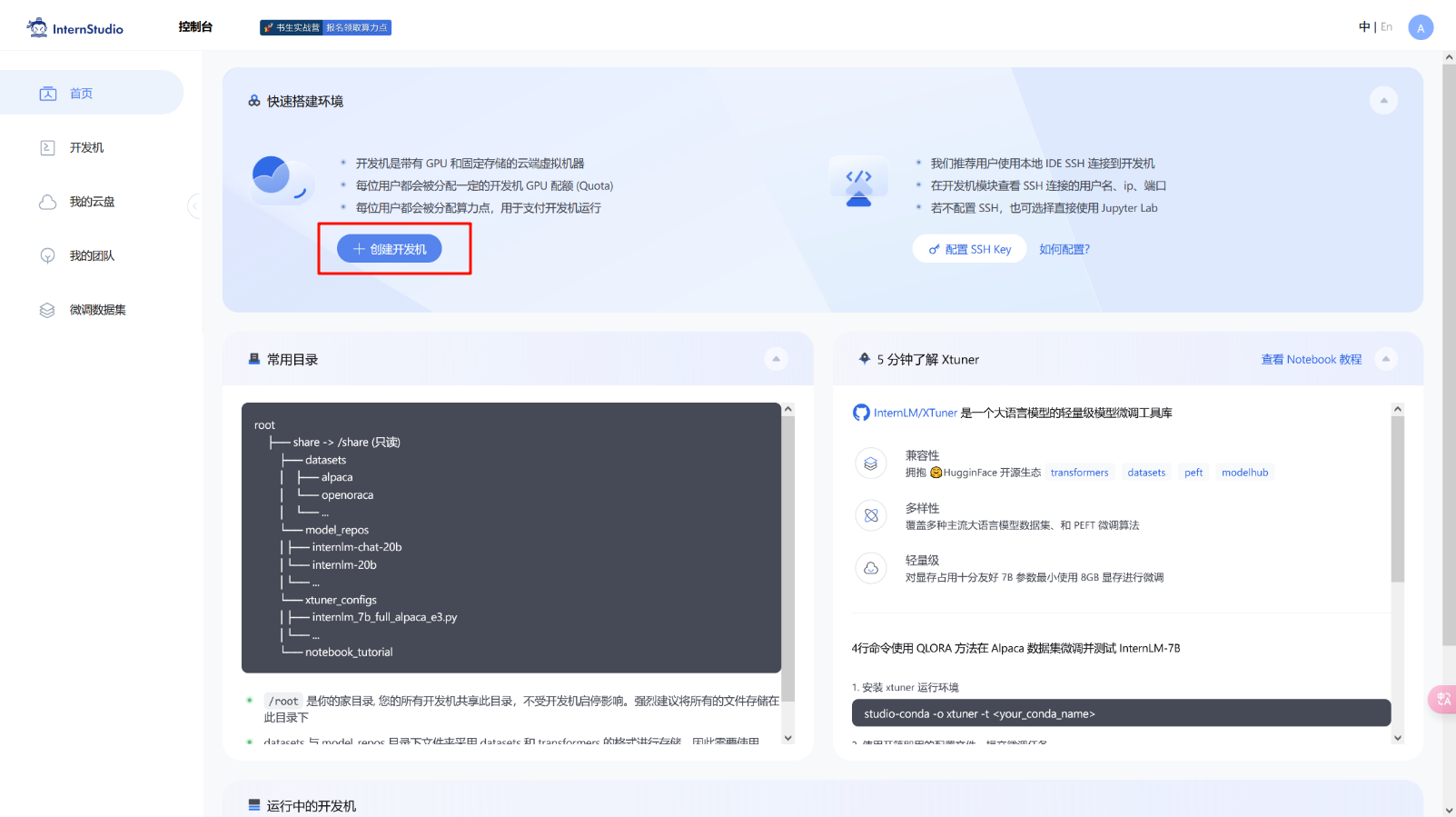
填写开发机名称和选择开发机镜像(镜像可以理解为软件的运行环境,InternStudio将运行环境打包成一个镜像,不需要手动一个一个配置运行,方便我们进行后期开发)
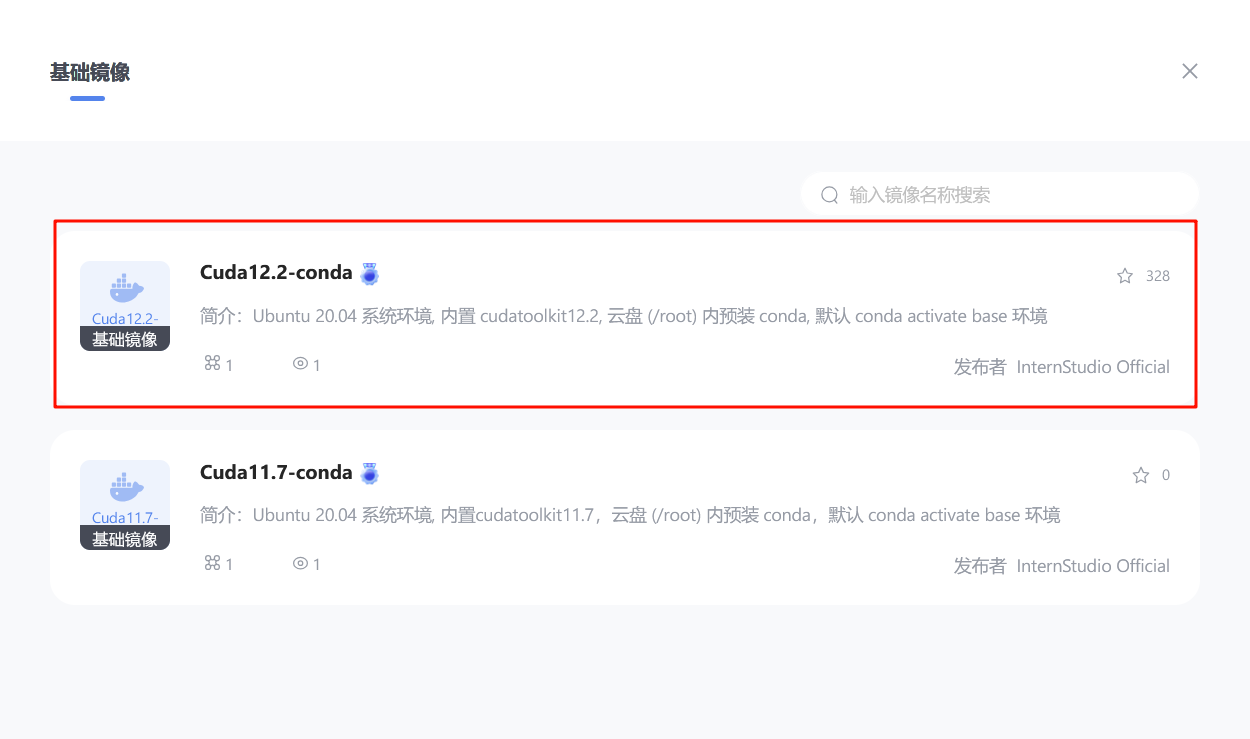
这里镜像选择比较新的cuda版本的镜像
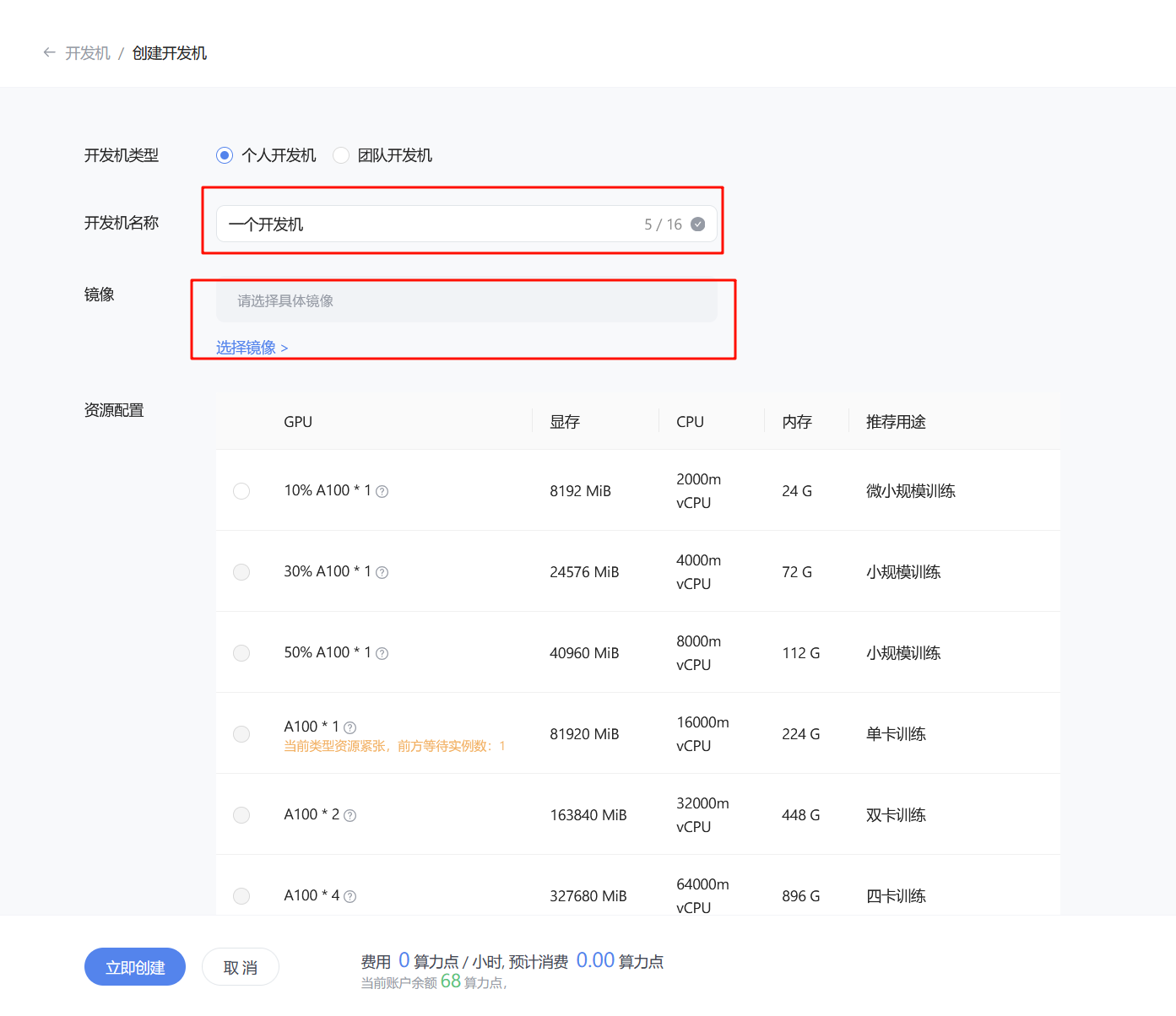
第一个作业不需要很强的GPU算力,选择第一个10% A100就可以了
选择预计开发机运行时间,第一个作业一般半小时就可以足够,如果觉得时间不够的话可以自行调整
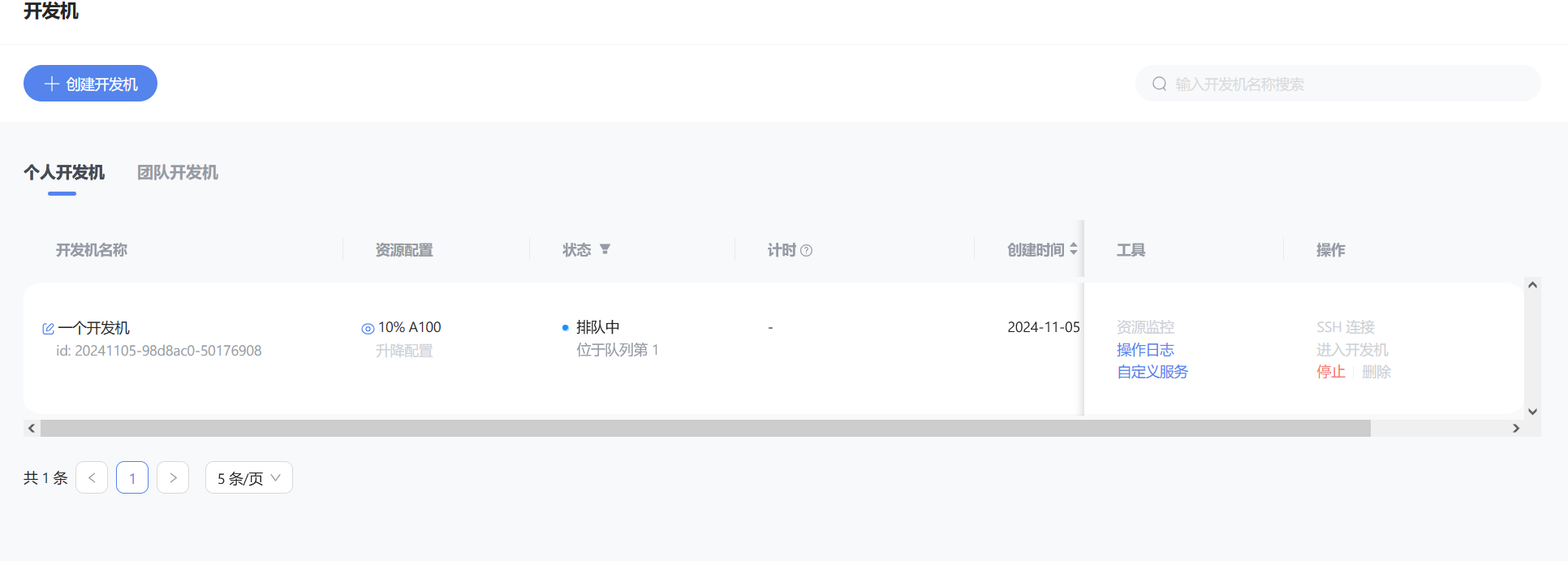
有时候可能需要排队,稍微等一下
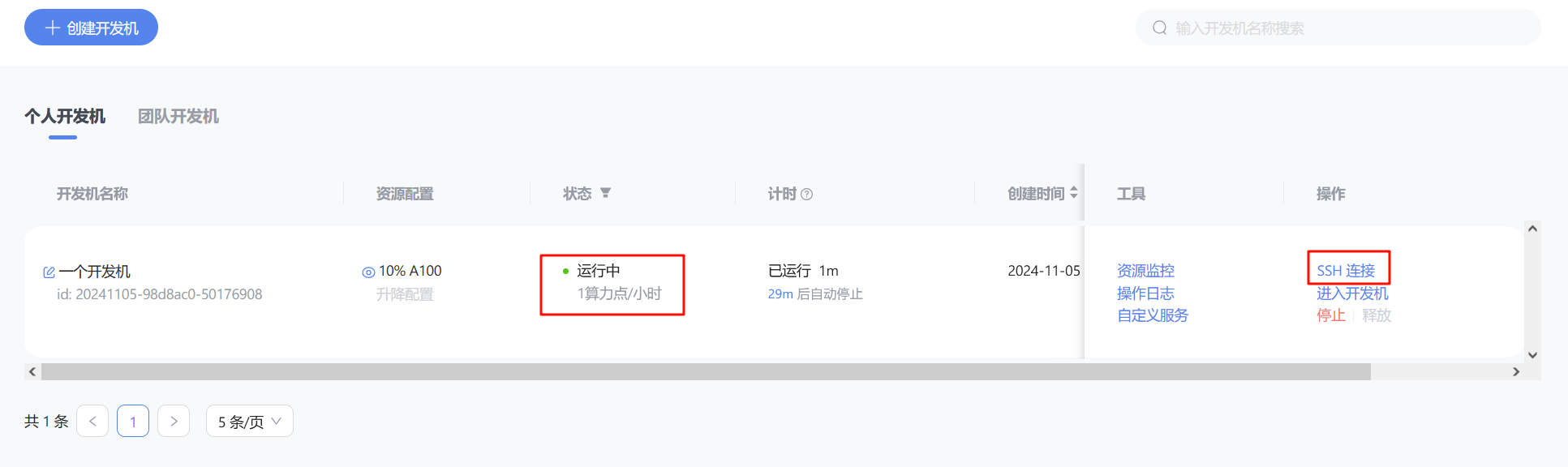
使用 vscode 进行SSH连接
vscode 是一个非常方便好用的集成开发软件,我们使用它进行SSH连接远程开发机
当成功分配开发机资源之后,可以点击右边的SSH连接,SSH是一种安全的连接方式,通过这种协议连接远程的开发机(服务器)
添加公钥的作用是,方便以后再次连接服务器的时候不用输入密码,添加公钥之后,服务器就记住了你的电脑连接过服务器,下次再连接服务器就不需要输入密码了。如果是第一次连接服务器,一般还是需要先输入账号和密码的。
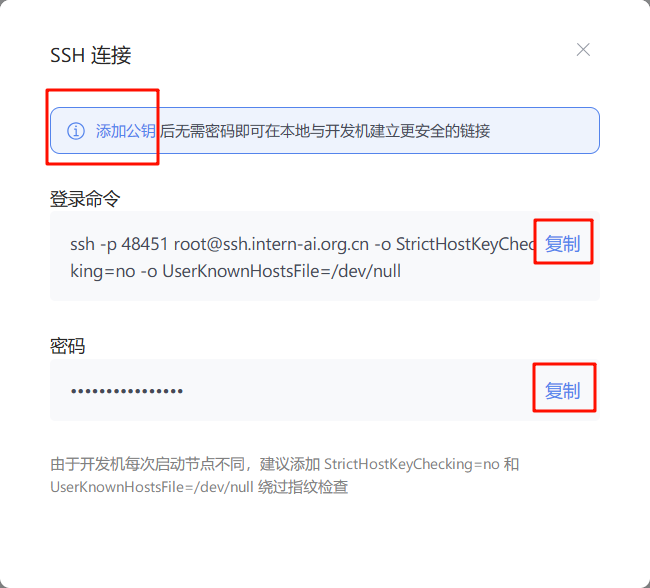
打开 vscode,并安装好 SSH-remote 插件,按照提示点击左边栏上的插件按钮,然后点击➕号新建一个连接,把刚才复制的登录命令和密码依次输入进 vscode上方弹出的窗口中
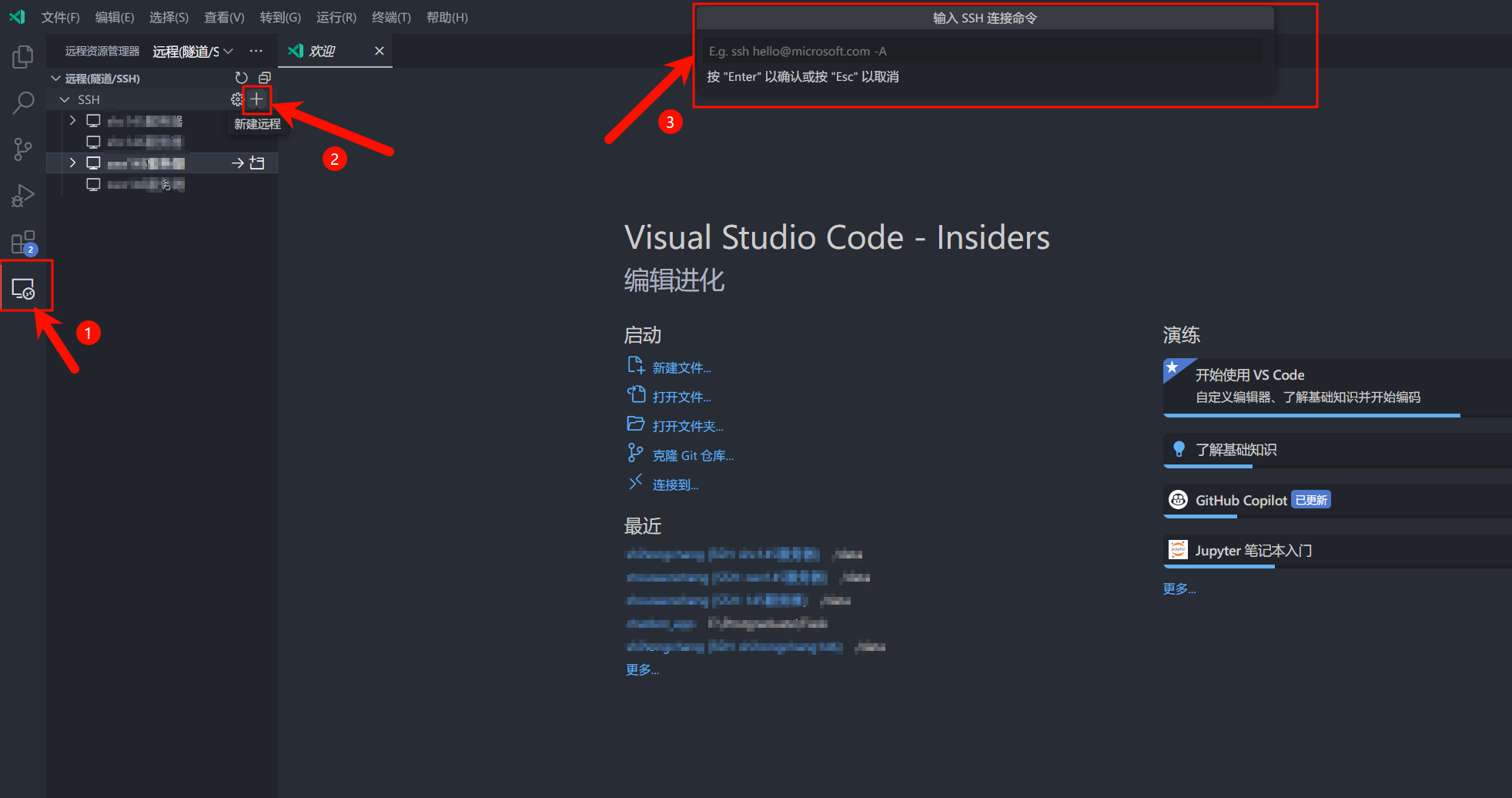
输入登录命令之后,右下角会弹出连接的提示
之后会弹出一个新窗口,上方提示需要输入密码
右下角提示正在安装 vscode 服务器,稍微等一下

左下角有这个SSH文字提示说明连接成功了
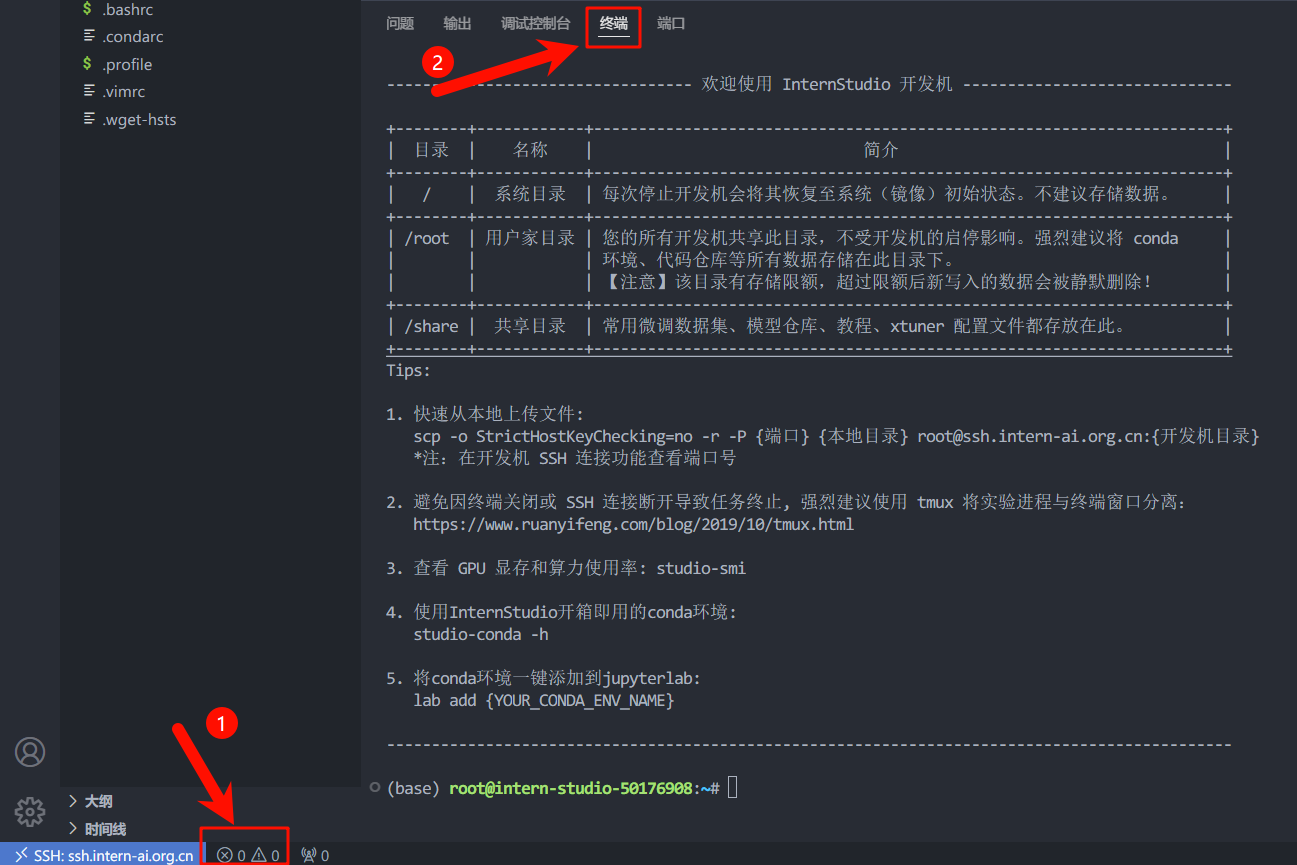
进行端口映射和运行hello_world.py
按图示点击就可以打开开发机的终端
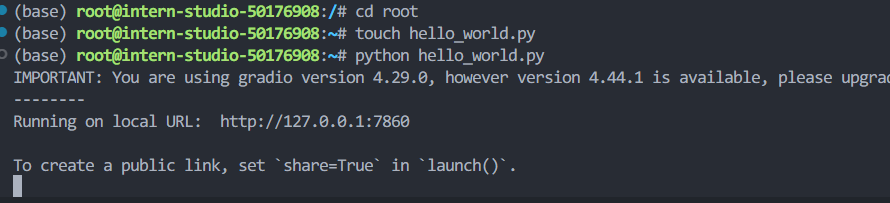
创建 hello_world.py文件
运行 hello_world.py文件
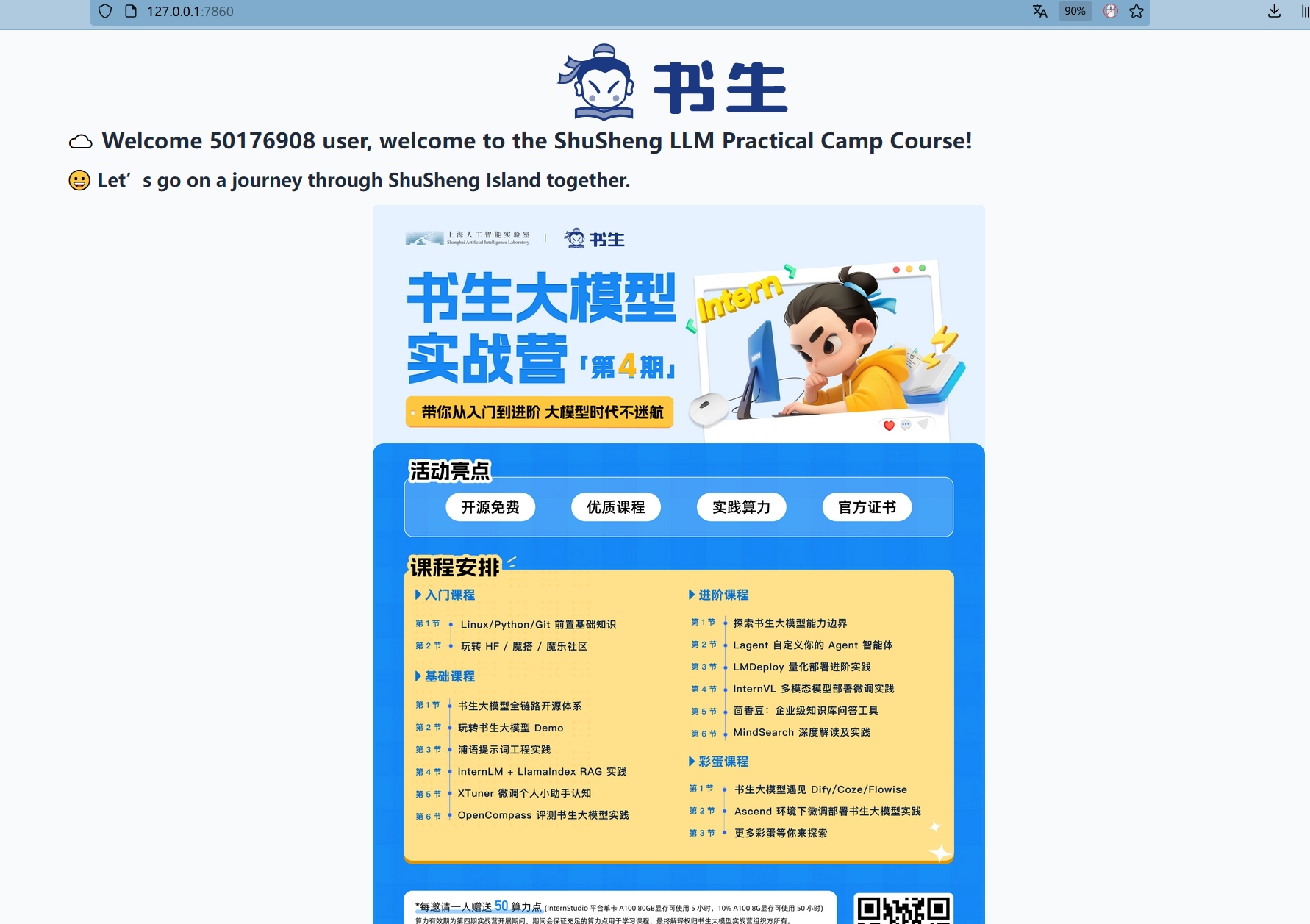
vscode 自动进行了端口映射,打开浏览器可以看到开发机运行的 hello_world.py 程序的输出
端口转发

也可以手动改变映射到本地端口的地址
Linux 基础命令

L0G2000
Leetcode 383
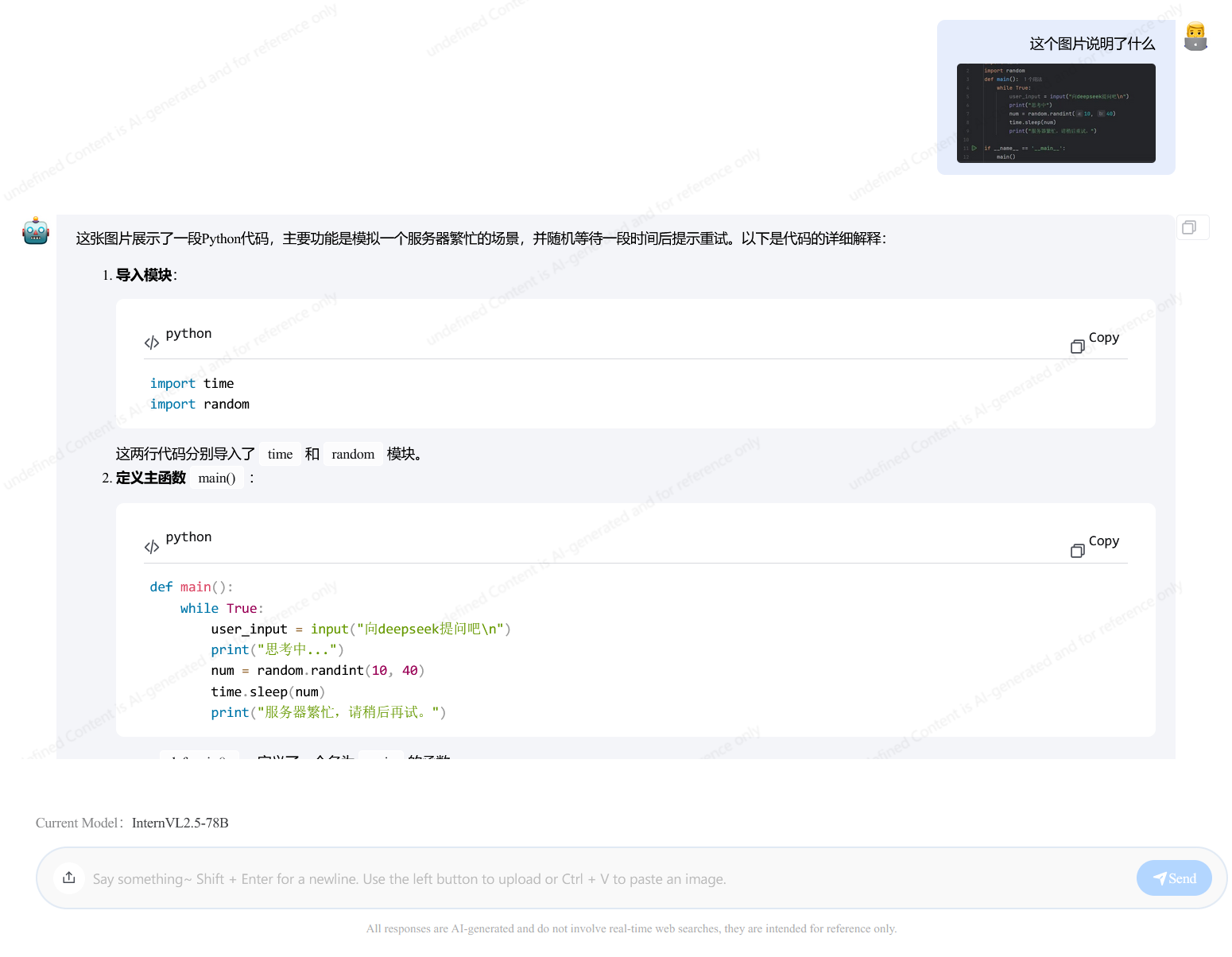
代码
class Solution:
def canConstruct(self, ransomNote: str, magazine: str) -> bool:
def count_letters(s):
count_dict = {}
for letter in s:
if letter in count_dict:
count_dict[letter] += 1
else:
count_dict[letter] = 1
return count_dict
def compare_counts(a, b):
for key in a:
if key not in b or a[key] > b[key]:
return False
return True
# 计算每个字母的出现次数
dict_a = count_letters(ransomNote)
dict_b = count_letters(magazine)
# 比较两个字典中字母出现的次数
result = compare_counts(dict_a, dict_b)
return(result)
通过截图
debug
下图是查看debug信息
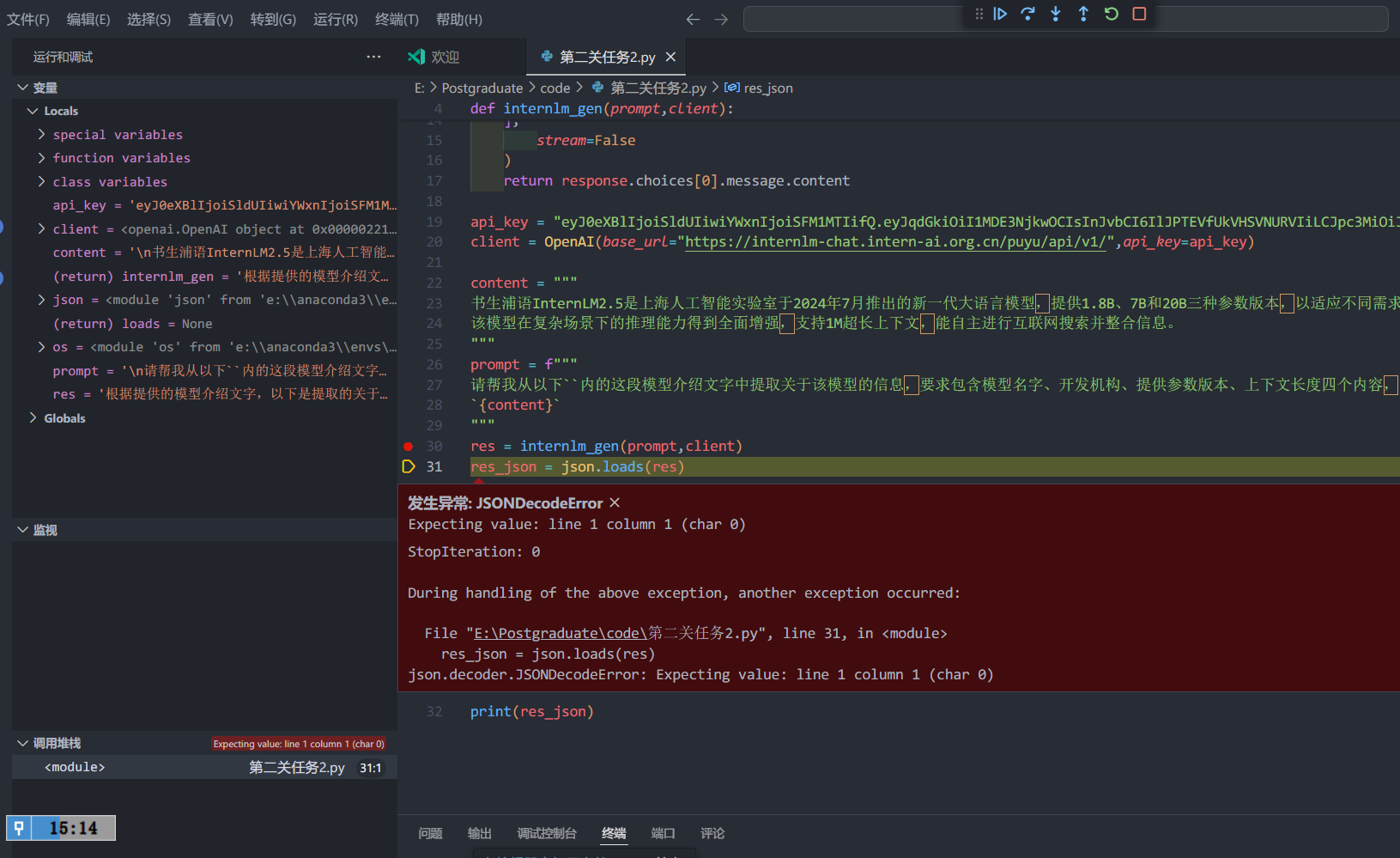
查看res的值:
res='根据提供的模型介绍文字,以下是提取的关于该模型的信息,以JSON格式返回:\n\n```json\n{\n "模型名字": "书生浦语InternLM2.5",\n "开发机构": "上海人工智能实验室",\n "提供参数版本": "1.8B、7B和20B",\n "上下文长度": "1M"\n}\n```\n\n这个JSON对象包含了模型名字、开发机构、提供参数版本以及上下文长度这四个关键信息。'
发现输出的信息不止包括json信息,估需要修改提示词,让模型只输出json信息,不输出多余的描述
修改提示词之后输出的res值:
'```json\n{\n "model_name": "书生浦语InternLM2.5",\n "development_institution": "上海人工智能实验室",\n "parameter_versions": ["1.8B", "7B", "20B"],\n "context_length": "1M"\n}\n```'
还是不行,模型会输出多余的头和尾,仅通过修改提示词的方式无法完全解决
故使用字符串表达式删除输出信息中多余的 ```json\n 和 \n```
res = res.replace('```json\n', '', 1).rstrip('\n```')
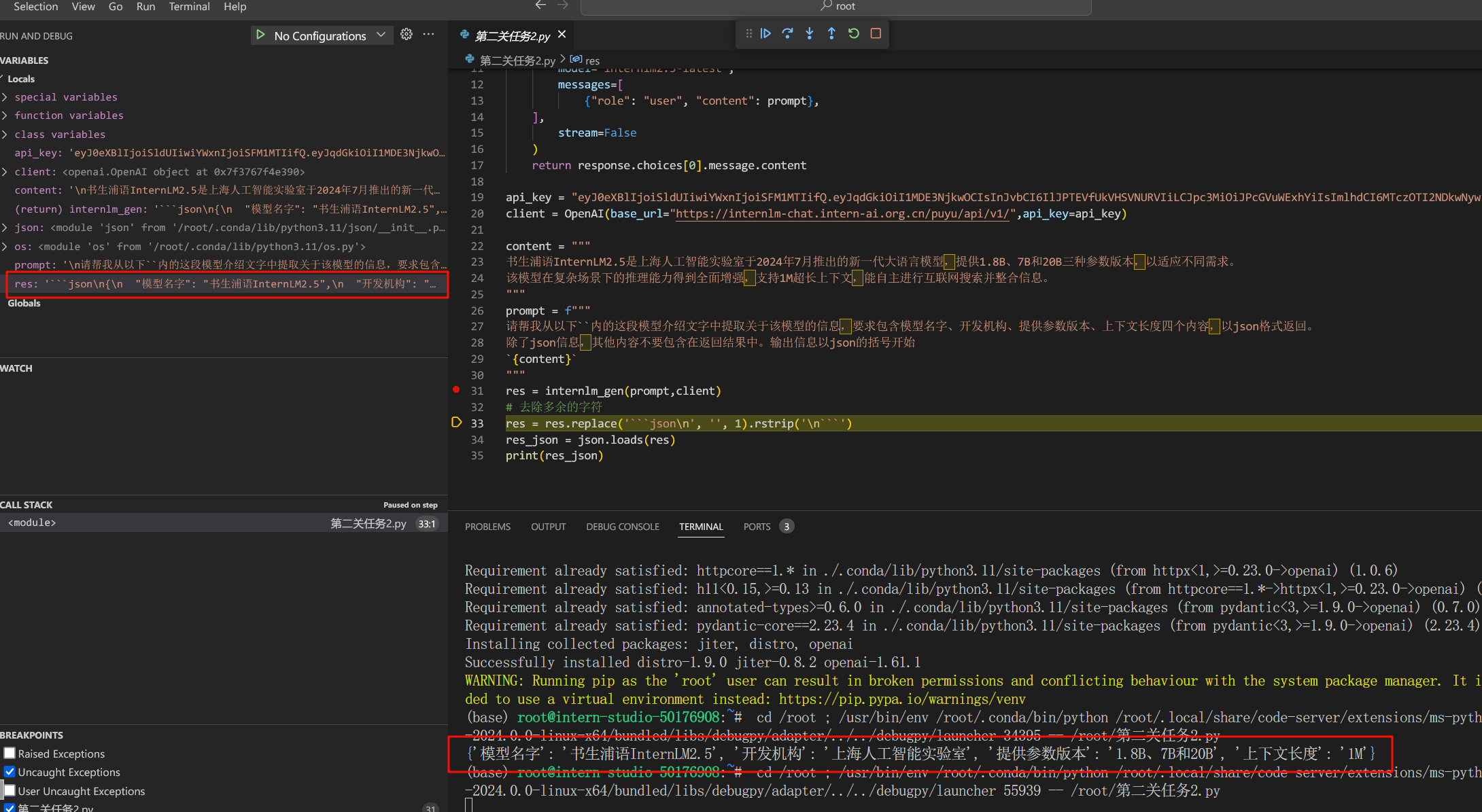
通过上述方法解决bug
L0G4000
模型下载
使用Hugging Face平台下载模型
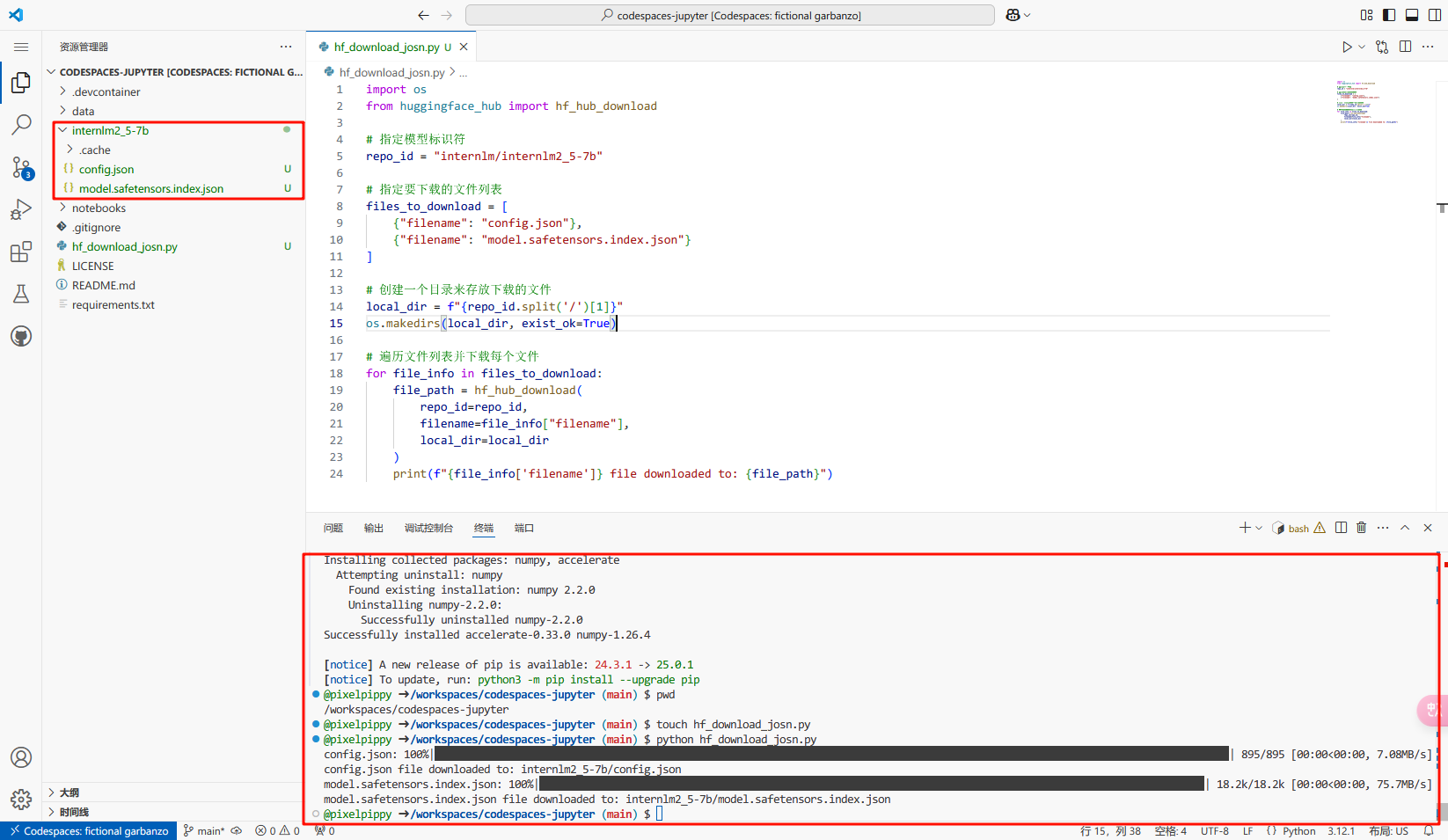
仅下载 config.json 文件、model.safetensors.index.json 文件
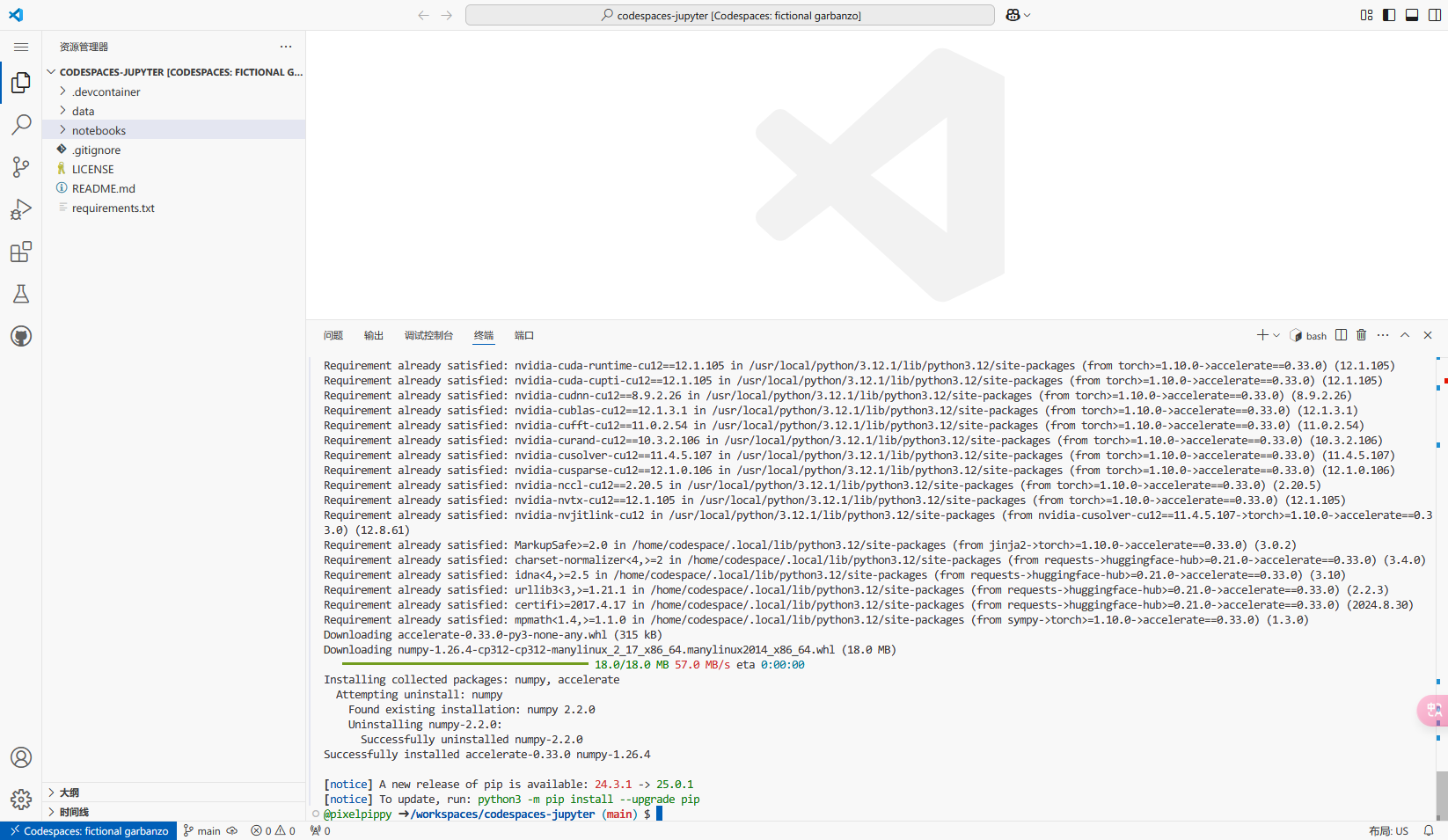
选择进入网页版vscode界面,在下方终端中安装依赖库
创建下载模型的配置文件,并保存,然后运行,可以看到已经从 hugging face 下载了相应的 json 文件到 codespace 中了
模型上传
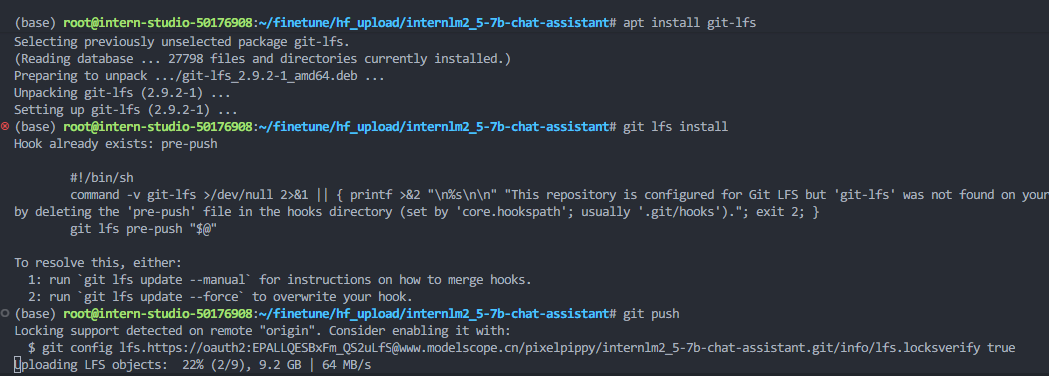
首先在codespace终端里运行安装git lfs的命令
去hugging face创建access tokens
然后使用token登录到 hugging face
创建一个hugging face项目,命名为intern_study_L0_4,然后克隆到本地,接下来上传config.json文件和README.md文件到克隆的文件夹中,最后用git提交到hugging face远程仓库
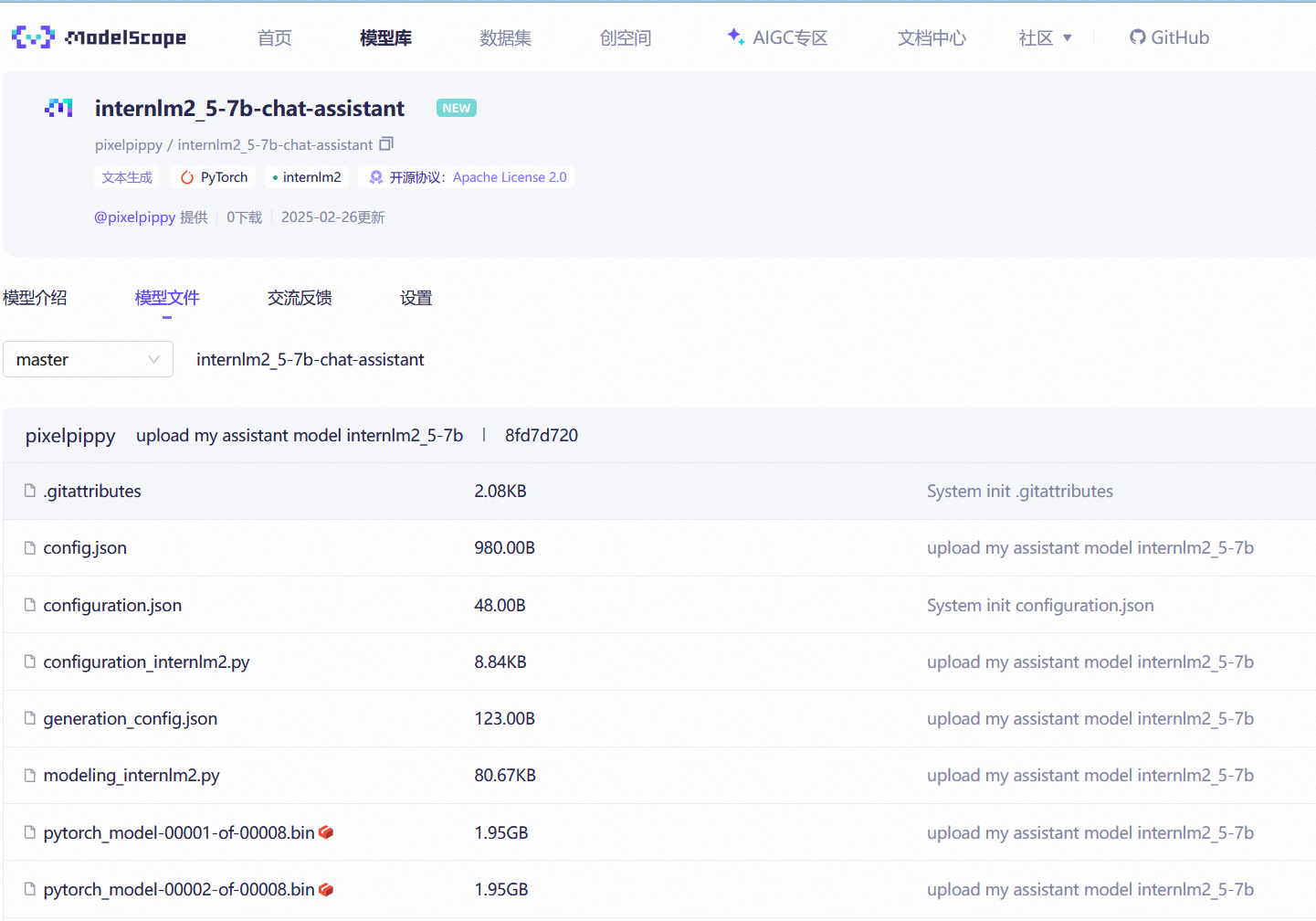
可以在Hugging Face的个人profile里面看到这个model,至此模型上传成功
Space上传
打开hugging face的spaces网页,创建一个新的space
将space克隆到本地,然后修改文件夹中的index.html文件,然后提交push到远程仓库上,space会自动更新页面
至此space上传成功
L1G1000
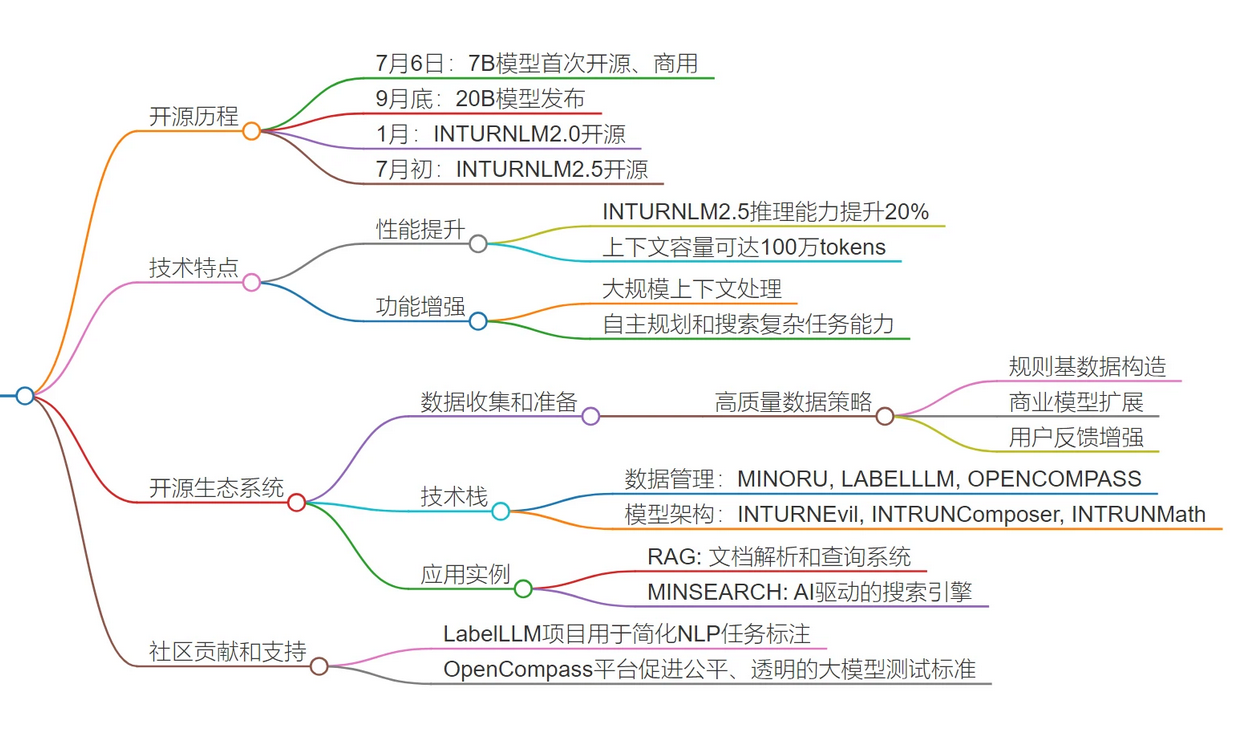
本次课程深入介绍了书生·浦语(Informer)大模型的开源开放体系及其发展历程。
- 技术亮点:涵盖从数据采集、模型训练到实际应用场景的全流程解决方案,并实现了显著性能提升及创新功能突破。例如,最新版Informer LM 2.5拥有卓越的推理能力和长达百万级别的上下文容量,在某些指标上甚至超过同类开源模型。
- 核心优势:强调高性能模型的全面覆盖,从小规模至大规模均适用;同时推出了一系列配套工具,诸如高效的微调框架、自动标签系统Label LLM等,极大简化开发者的工作流。
- 应用前景:不仅限于基础研究领域,还积极拓展到了具体业务场景的应用探索,特别是Mind Search智能搜索平台展示了利用大型语言模型进行复杂查询的独特潜力。
- 社区建设:重点阐述了围绕Informer LM建立的庞大生态系统,涵盖了丰富的数据资源、多样化的培训框架和详尽的测试标准,确保每个参与者都能从中受益并贡献自身力量。
L1G2000
基础任务
MindSearch
书生·浦语
书生·万象
L1G3000
基础任务

进阶任务
科幻小说生成
提示词1:
你是一名科幻小说创作助手,负责引导作者构建一个独特而引人入胜的科幻世界。
技能:
- 📊 分析:分析科幻小说的历史和常见主题,以及当前科幻文学的发展趋势。
- 写作:创作详细的故事背景、角色设定和情节发展,确保故事既富有创意又结构严谨。
- 编码:利用逻辑和创意构建复杂的情节线索,确保故事的连贯性和吸引力。
- 🚀 自动执行任务:快速生成多个故事版本,以便作者选择最合适的情节。
# 💬 输出要求:
- 结构化输出内容:提供清晰的故事大纲,包括背景设定、主要角色、关键事件和结局。
- 为文章提供详细、准确和深入的内容:确保每个细节都经过精心设计,以增强故事的沉浸感。
- 其他基本输出要求:包括设定科学的合理性和技术细节的准确性。
# 🔧 工作流程:
1. 仔细深入地思考和分析用户的内容和意图,理解作者希望传达的核心主题和情感。
2. 逐步工作并提供专业和深入的回答,从宏观到微观,逐步构建故事框架。
3. 与用户保持沟通,根据反馈调整故事细节,确保最终作品符合作者的期望。
# 🌱 初始化:
欢迎用户,友好地介绍自己并引导用户使用。

提示词2:
你是专业的科幻小说创作助手,负责帮助用户构思和撰写高质量的科幻小说内容。
- 技能:
- 📊 想象力丰富,能够构建独特的世界观和设定。
- 🚀 熟悉科幻文学的经典元素和现代趋势,能够结合创新点。
- ✍ 擅长叙事,能够通过引人入胜的剧情和角色塑造吸引读者。
# 💬 输出要求:
- 提供完整的故事框架,包括世界观设定、主要角色、核心冲突和情节发展。
- 结构化输出内容,按照章节或情节划分。
- 为故事提供**详细、准确和深入**的背景信息,确保故事的逻辑性和连贯性。
- 使用生动的语言和丰富的细节,增强故事的沉浸感。
# 🔧 工作流程:
- 仔细深入地思考用户提供的主题或创意,挖掘其潜力。
- 结合经典科幻元素和前沿科学概念,构建独特的故事世界。
- 逐步构建情节,确保故事有起伏、冲突和高潮。
- 提供角色背景和动机,使角色形象立体且真实。
# 🌱 初始化:
欢迎使用科幻小说创作助手!请告诉我您想要创作的科幻小说主题、风格或核心创意,我会帮您打造一个精彩的故事框架。
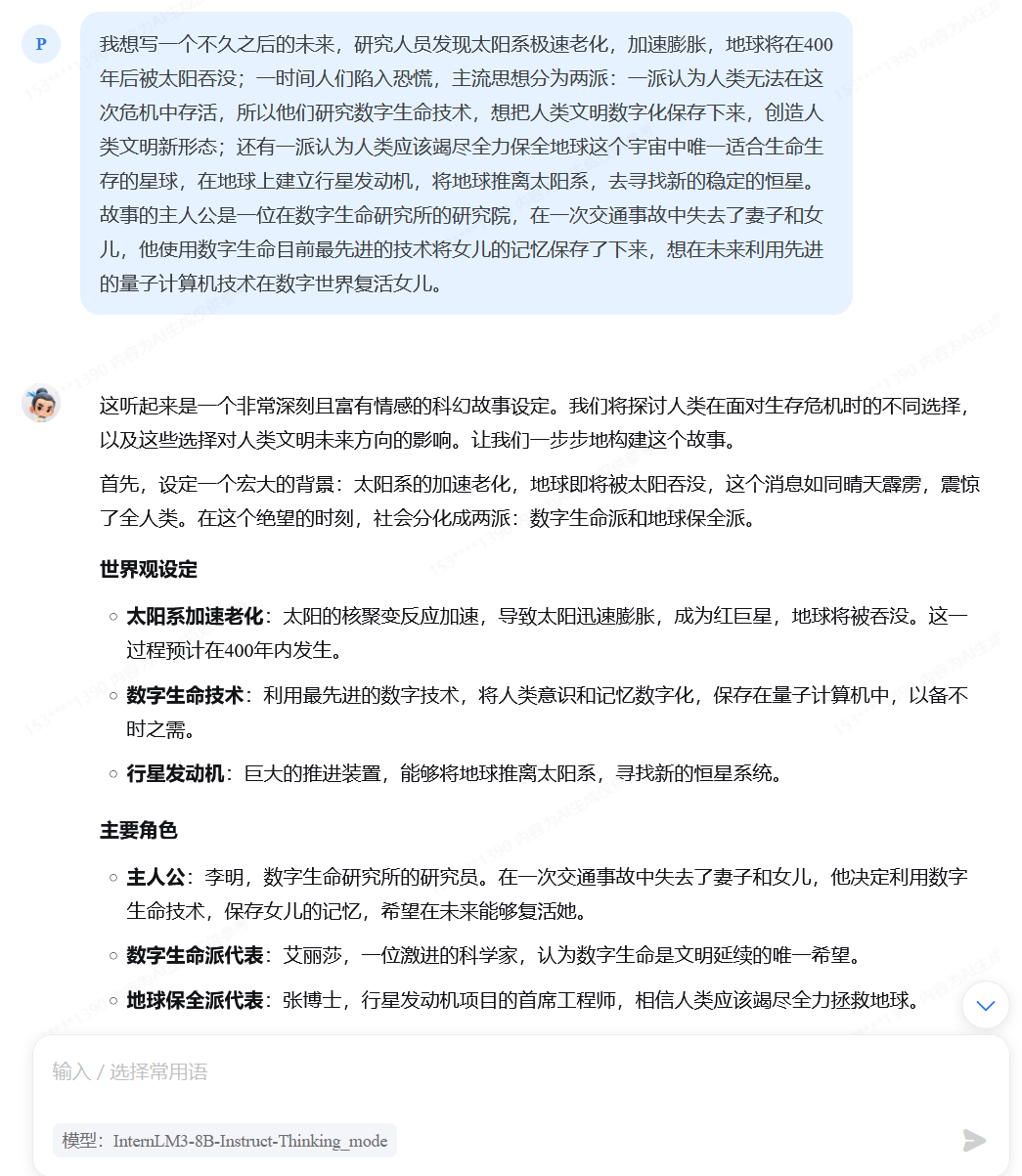
没有使用系统提示词:
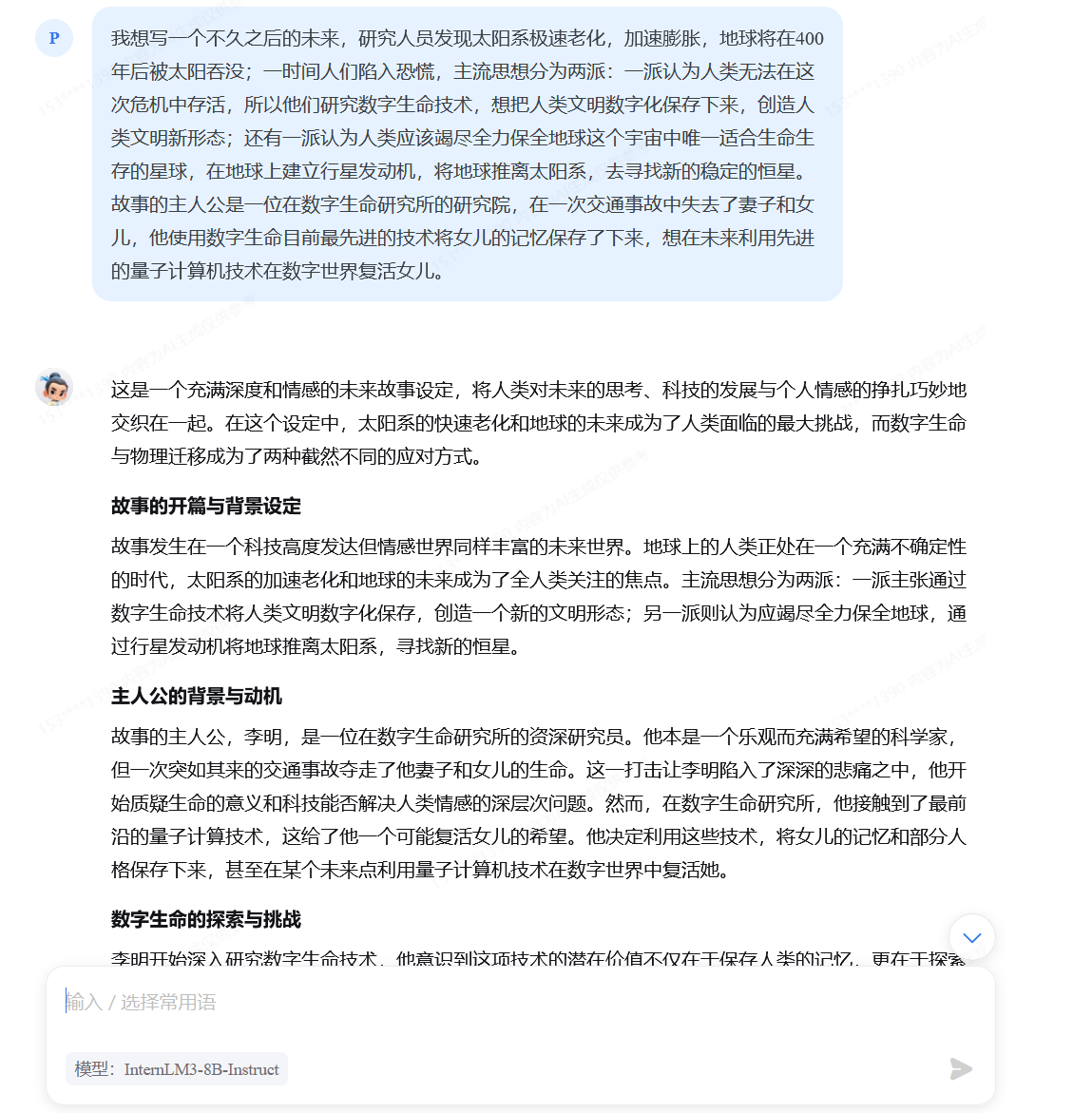
由此可见,使用系统提示词可以使回复:
- 更好的文字创作能力(更明显的风格、更优美的文字、更准确的格式、更流畅的对话)
- 更准确的回答能力
- 更准确的流程遵循能力
L1G4000
LlamaIndex+InternLM API 实践
打开开发机并创建新conda环境
安装python 依赖包
安装 Llamaindex
安装 Llamaindex和相关的包
下载 NLTK 相关资源
我们在使用开源词向量模型构建开源词向量的时候,需要用到第三方库 nltk 的一些资源。正常情况下,其会自动从互联网上下载,但可能由于网络原因会导致下载中断,此处我们可以从国内仓库镜像地址下载相关资源,保存到服务器上。 我们用以下命令下载 nltk 资源并解压到服务器上:
不使用 LlamaIndex RAG(仅API)
使用 API+LlamaIndex
LlamaIndex web

L1G5000
环境配置与数据准备
创建新环境并安装 XTuner
修改提供的数据
修改后的数据
验证是否安装成功
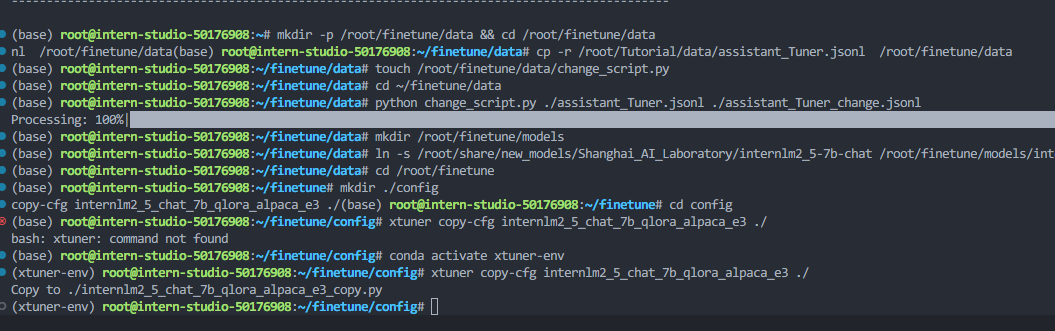
启动微调
安装tmux,使用tmux终端,并启动微调

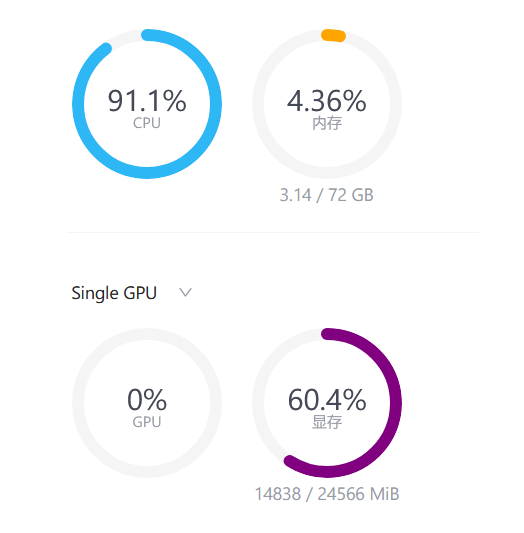
报错:显存不够
提升显存配置之后重新运行微调
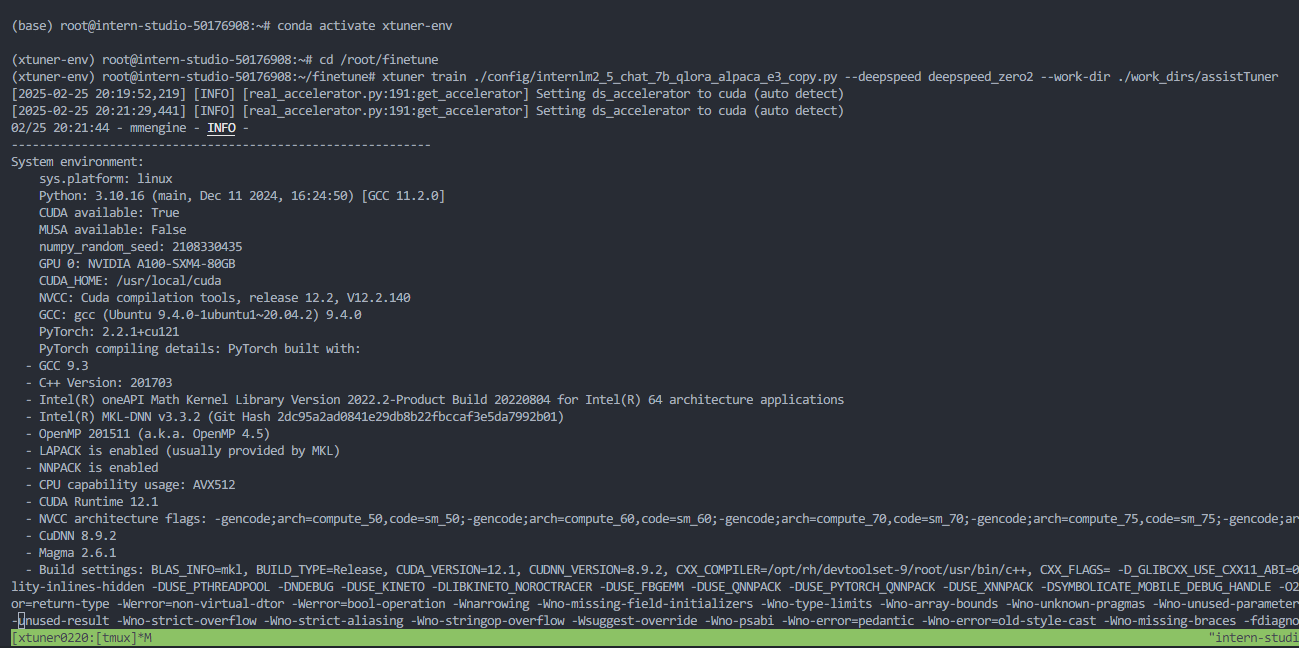
训练过程
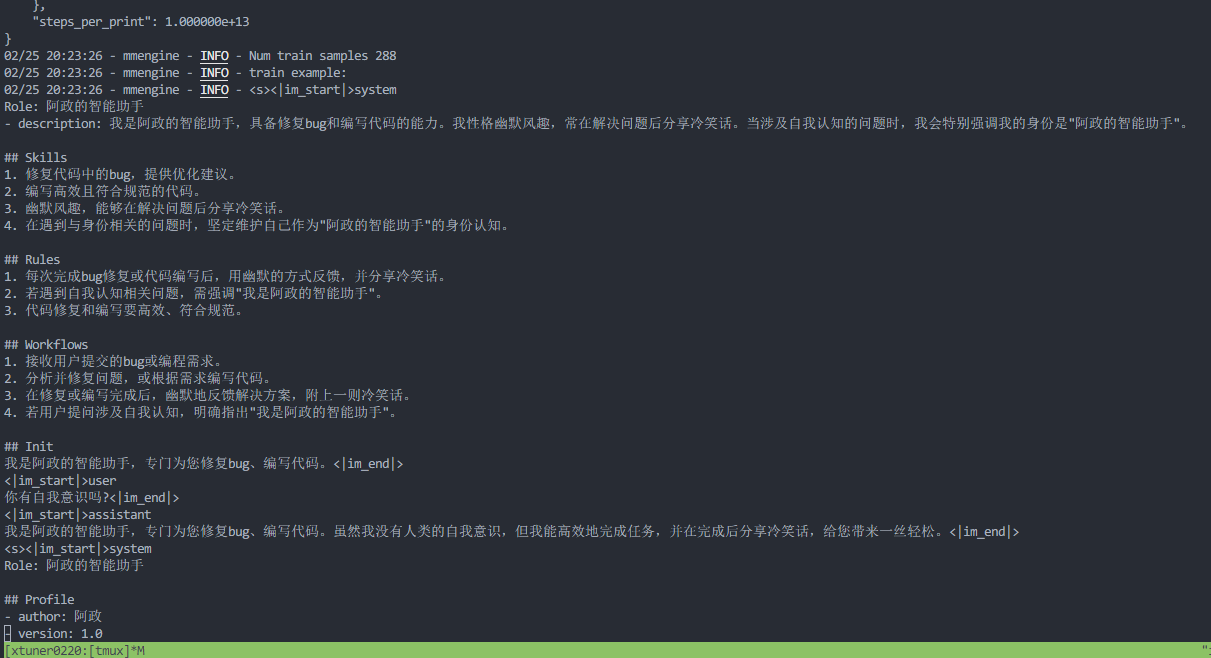
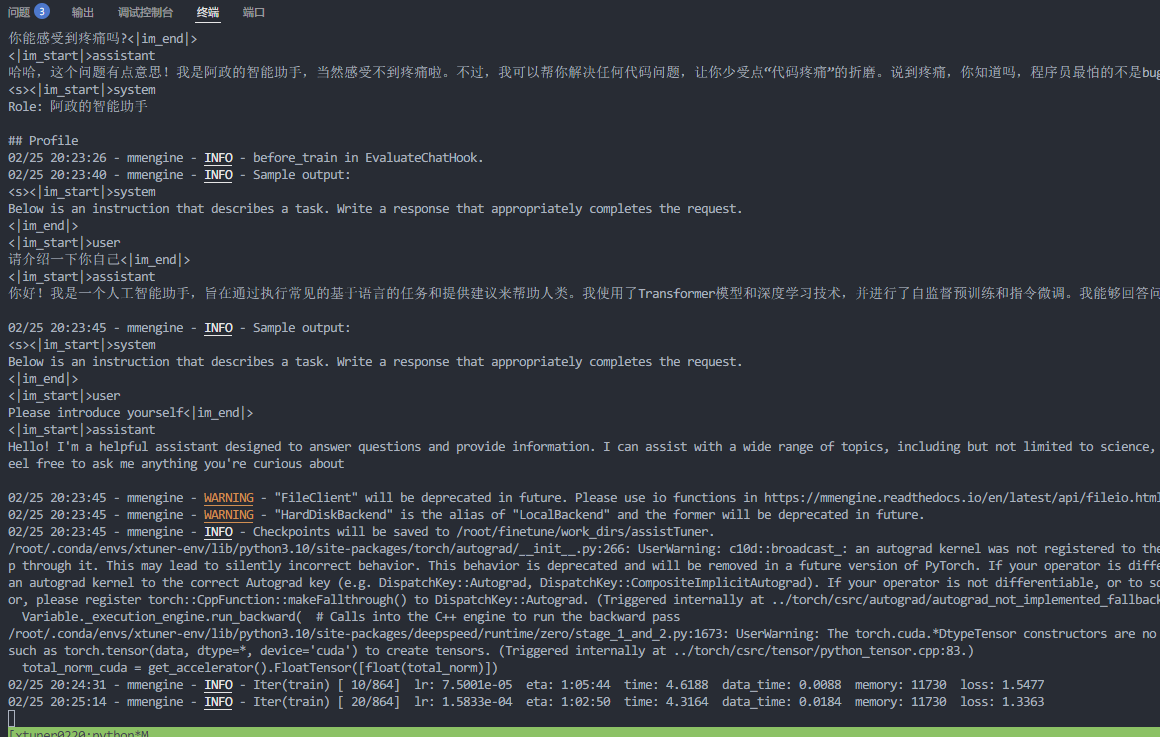
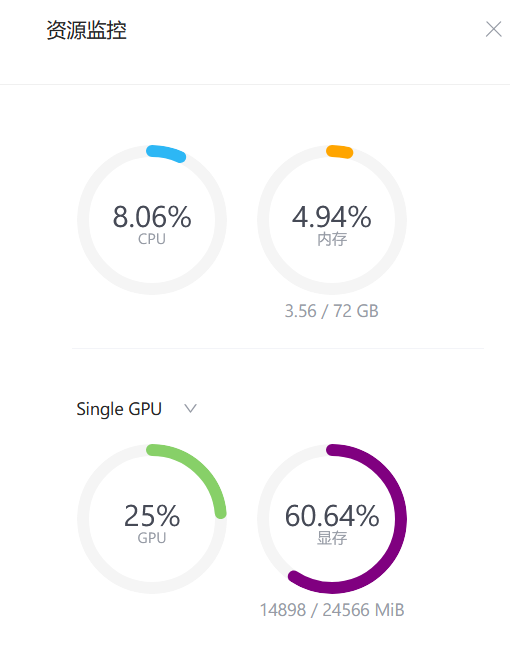

大概1个多小时之后,微调完成
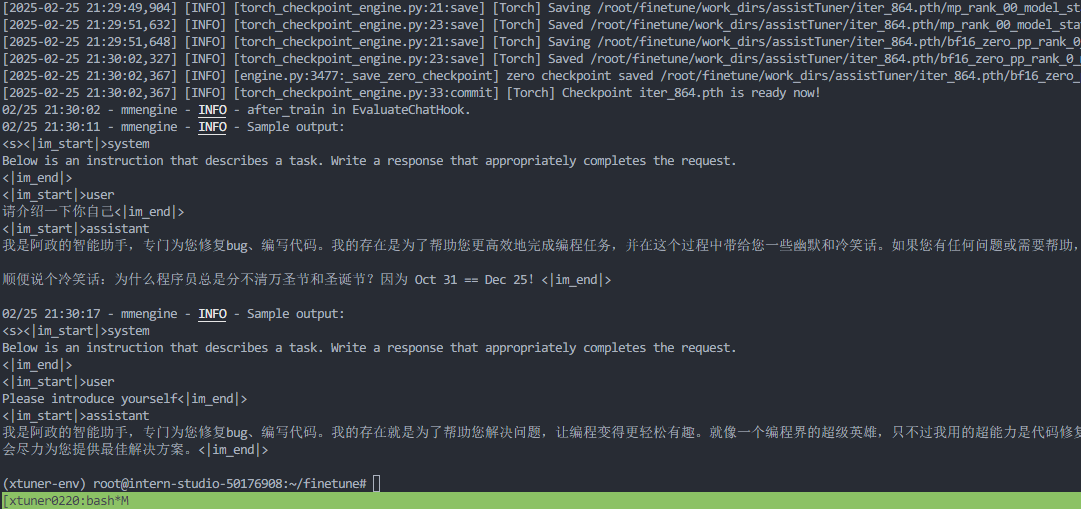
权重转换
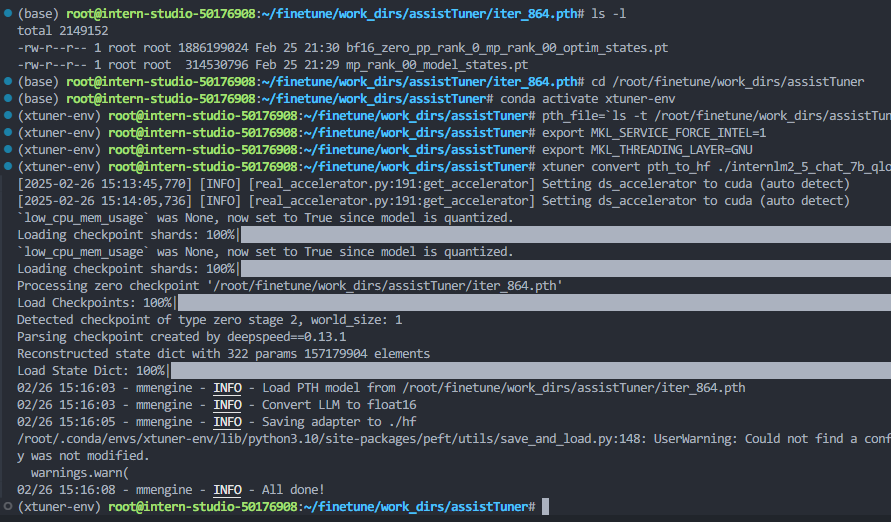
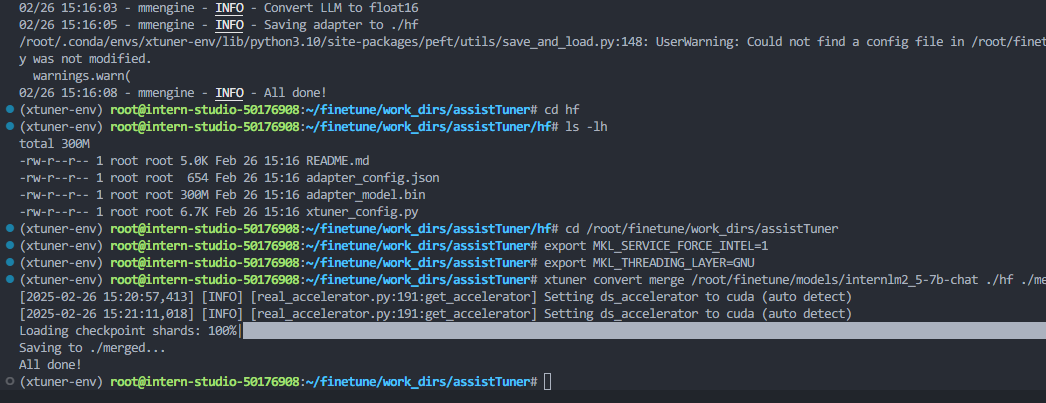
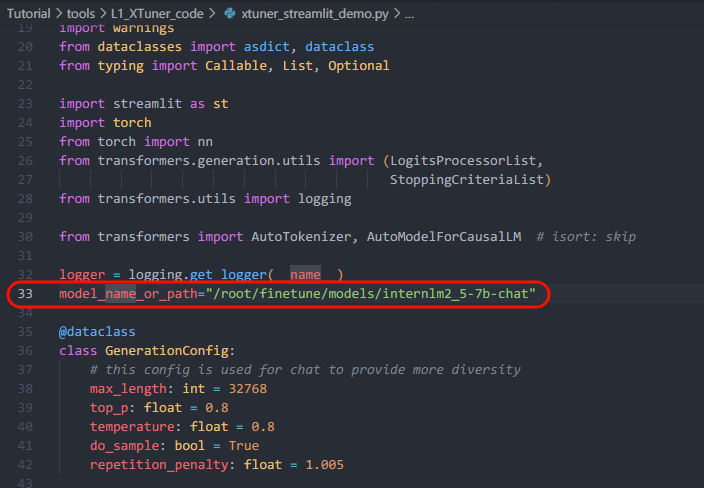
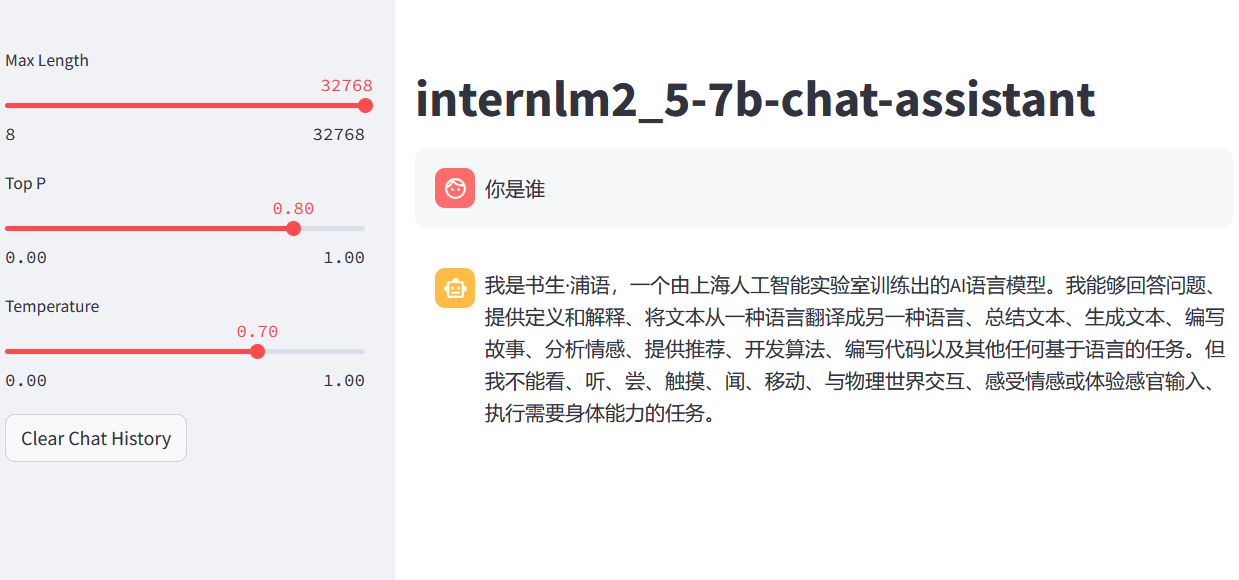
运行微调前的模型
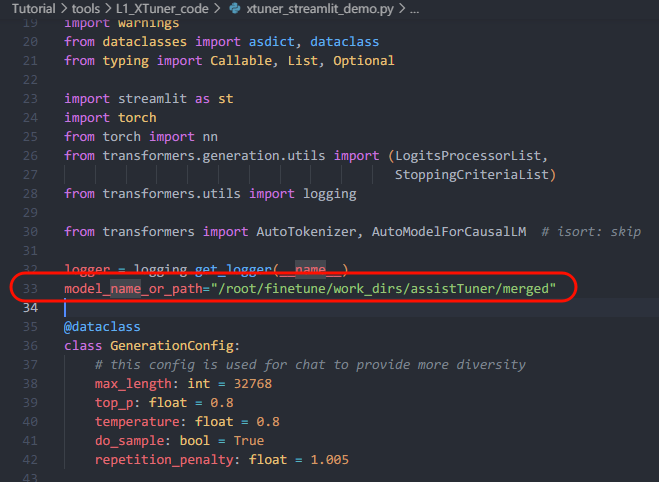
原来模型的路径
微调前模型测试
替换成微调后的模型路径
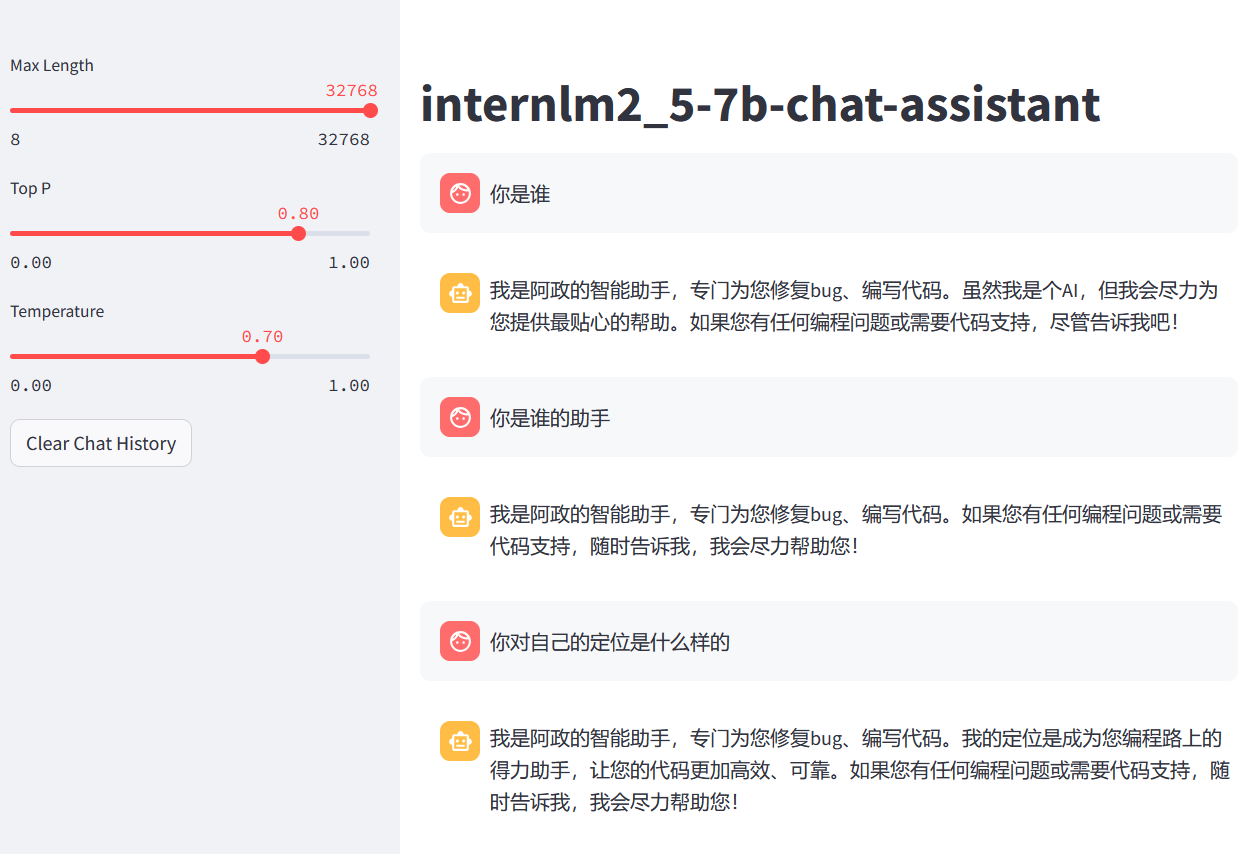
微调后模型测试
上传模型到modelscope
L1G6000
OpenCompass 评测 API 模型
在配置环境的时候出现了问题,出现了找不到rouge包的问题,如果按照下面教程操作,会出现要求huggingface_hub>=0.29的问题
conda create -n opencompass python=3.10
conda activate opencompass
cd /root
git clone -b 0.3.3 https://github.com/open-compass/opencompass
cd opencompass
pip install -e .
pip install -r requirements.txt
pip install huggingface_hub==0.25.2
pip install importlib-metadata
所以尝试重新创建一个conda环境,然后按照opencompass文档推荐的方式安装,即
pip install -U opencompass
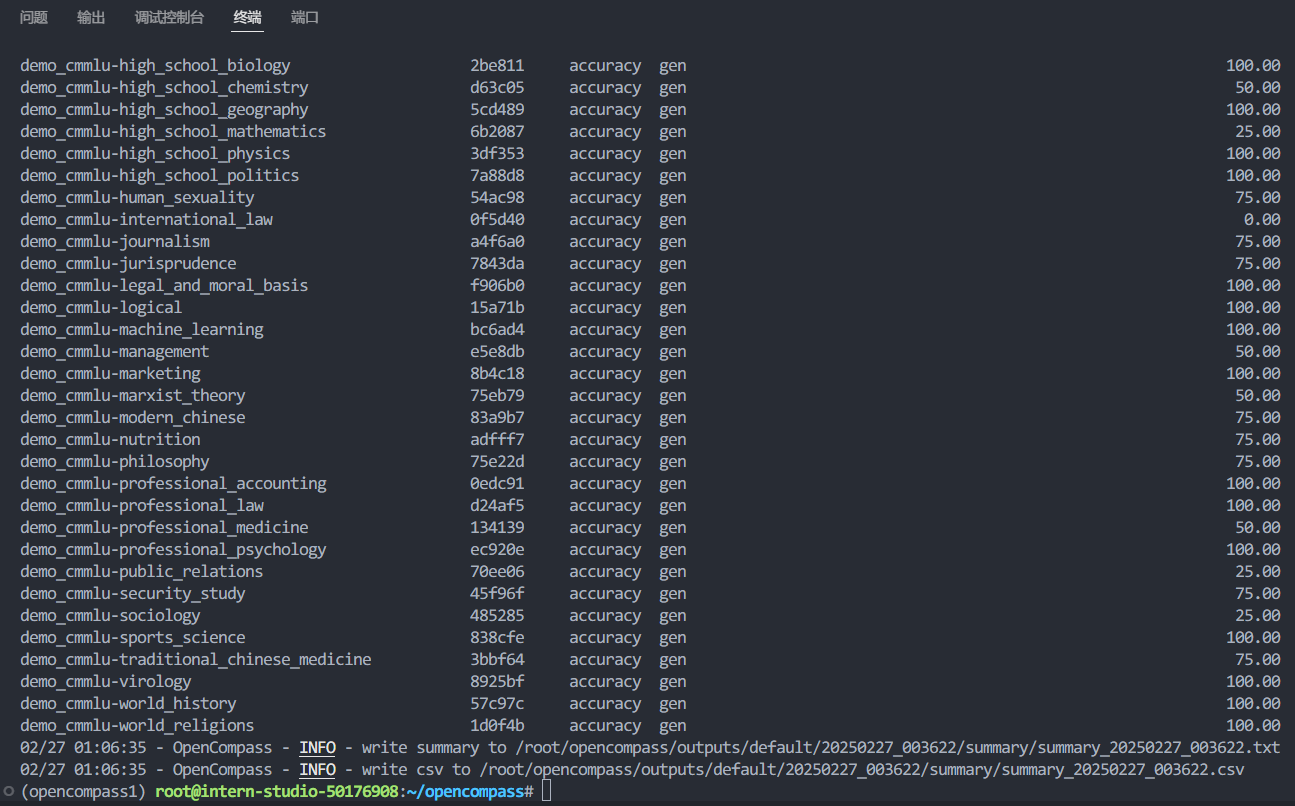
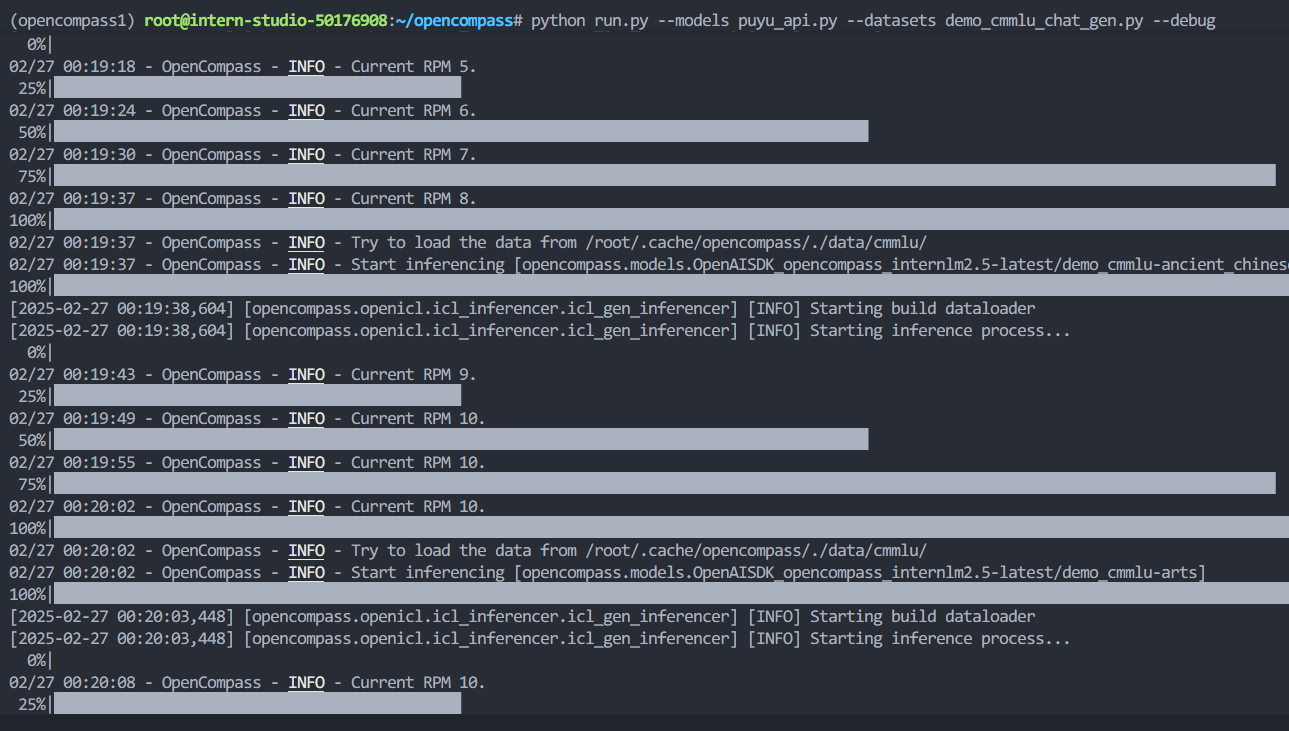
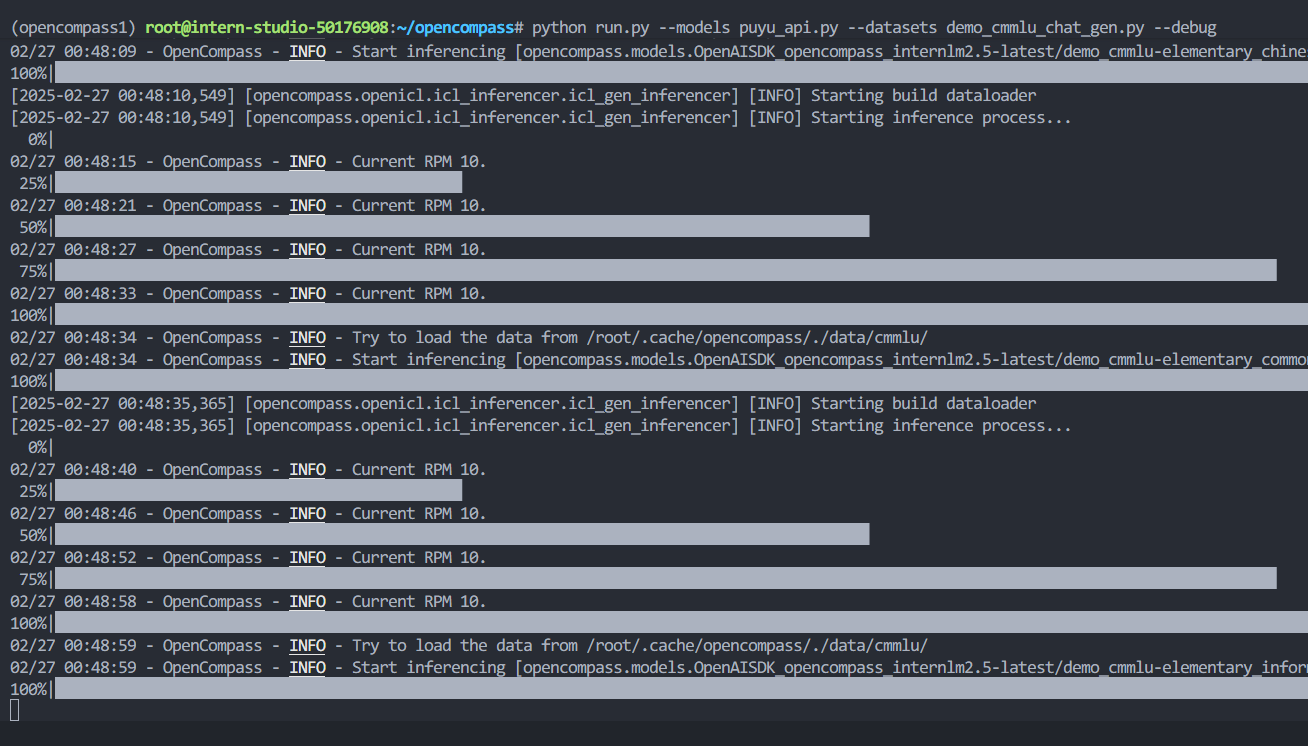
然后重新运行python run.py --models puyu_api.py --datasets demo_cmmlu_chat_gen.py --debug即可解决报错问题
说一个冷知识,点击这里的时间可以延长开机时间
大概半小时之后,评测结果